llama.cpp (Cortex)
Overview
Jan uses llama.cpp for running local AI models. You can find its settings in Settings () > Local Engine > llama.cpp:
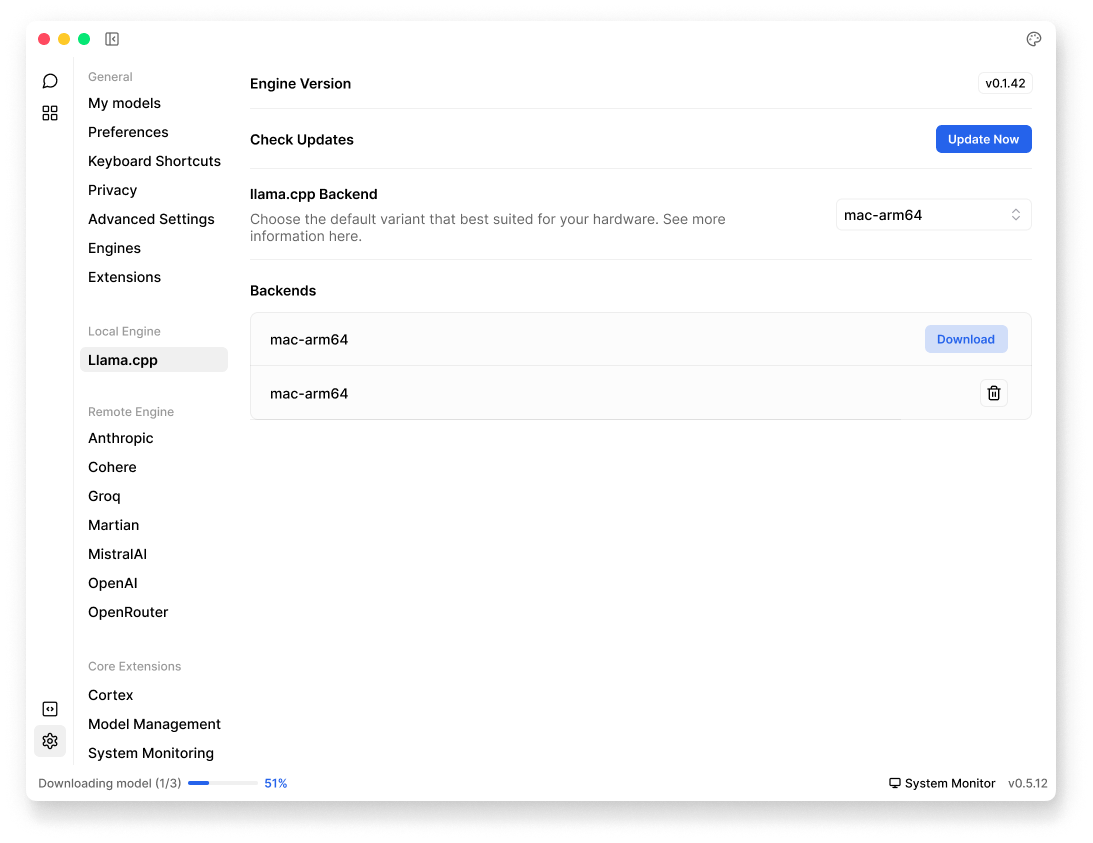
These settings are for advanced users, you would want to check these settings when:
- Your AI models are running slowly or not working
- You've installed new hardware (like a graphics card)
- You want to tinker & test performance with different backends
Engine Version and Updates
- Engine Version: View current version of llama.cpp engine
- Check Updates: Verify if a newer version is available & install available updates when it's available
Available Backends
Jan offers different backend variants for llama.cpp based on your operating system, you can:
- Download different backends as needed
- Switch between backends for different hardware configurations
- View currently installed backends in the list
⚠️
Choose the backend that matches your hardware. Using the wrong variant may cause performance issues or prevent models from loading.
macOS
mac-arm64: For Apple Silicon Macs (M1/M2/M3)mac-amd64: For Intel-based Macs
Windows
win-cuda: For NVIDIA GPUs using CUDAwin-cpu: For CPU-only operationwin-directml: For DirectML acceleration (AMD/Intel GPUs)win-opengl: For OpenGL acceleration
Linux
linux-cuda: For NVIDIA GPUs using CUDAlinux-cpu: For CPU-only operationlinux-rocm: For AMD GPUs using ROCmlinux-openvino: For Intel GPUs/NPUs using OpenVINOlinux-vulkan: For Vulkan acceleration